

Neural Machine Translation Blog Series – Part 1
This blog is the first part in our new series on Neural Machine Translation and its impact on LSPs in the life science industry.
What is NMT?
Neural Machine Translation (NMT) is an approach to automated translation that uses machine learning to translate text from one language into another. A division of computational linguistics, NMT relies on artificial neural networks, themselves modelled on the human brain, to predict the likelihood of certain sequences of words. The MT algorithm is an example of deep learning: users can train NMT engines to recognise source and target connections using large datasets. As connections between words are strengthened or weakened through training on the datasets, the machine observes these correlations and adapts to predict and increase the likelihood of correct translations (Lommel, 2017).
Historically, there have been several incarnations of the machine learning model. Examples include the Fully Automated Machine Learning (FAMT), performed automatically without human intervention, and Computer Assisted Translation (CAT), which is completely dependent on human input and aims to support rather than replace the human linguist in the translation workflow. Of these, statistical machine translation (SMT) was the dominant paradigm prior to NMT, and perhaps its most important precursor. Like neural machine translation, SMT also relies on probabilistic language and analysis of mono- and bilingual training data to ‘learn’ what makes a good translation (España-Bonet, C. and Costa-jussà, M.R., 2016: 6). However, advances in Artificial Intelligence (AI) made it possible to emulate the structure of human neural networks and move towards a more integrated approach to machine learning.
How NMT works
NMT functions by predicting how likely certain word sequences are, based on patterns observed in the datasets used for its training. A key mechanism is vector representation. In NMT, words are transcribed into vectors, each with a unique magnitude and direction, in a process of encoding and decoding. The engine analyses the source text input, encodes it into vectors, then decodes it into target text by predicting the likely correct translation.
Although it still incorporates probabilistic models, NMT differs from other statistical-based MT by assessing input as a whole, rather than separating it into sub-components. It can thus identify connections between words, which are strengthened or weakened depending on which words occur together. As a result, a trained NMT engine could ultimately make choices based on the strength of this contextual information to produce accurate, quality outputs. Figure 1 below outlines this process of identifying connections in NMT.
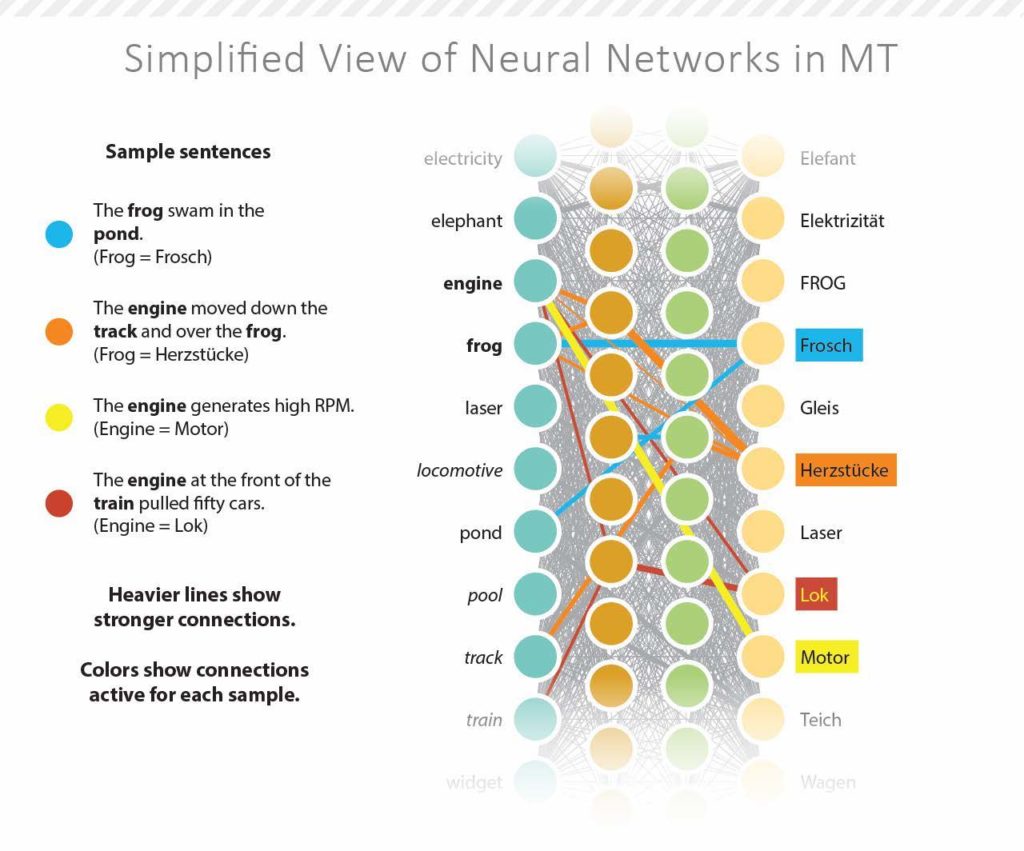
Figure 1: Neural Networks Use Connection Strength and Relationships to Translate (Source: Common Sense Advisory, Inc.)
NMT engines rely on training materials to learn to produce quality output. It follows that the performance of the engine depends on the quality of the datasets used for training. This in turn raises questions about the quality of MT output, an issue that is particularly salient for medical and pharmaceutical translations where patient safety is of utmost importance. We look at quality standards in NMT more in-depth in the section below.
NMT Myth-busting
Any new technology is vulnerable to misinterpretation. This is especially true for NMT, and machine learning in general, as it brings to mind the shifting of roles between AI and humans. Perhaps it’s precisely the sensitivity of the topic that gives rise to misconceptions that tend to stick in the public consciousness, so it’s worth looking at some of the more common myths in detail.
Myth 1: Machine translation is just not good enough
A common argument against machine translation is its perceived lack of quality. Critics argue that translations produced automatically are clumsy, awkward, and at worst inaccurate, as the machine does not have the ability to distinguish between similar translation choices or detect nuances in meaning. An oft-cited example is Google Translate, seen as a generic, singular example of machine translation. Since it cannot meet the specific requirements of a number of professional industries, many reject machine learning from the outset.
There are three main points to address these quality concerns.
First, the use of customised systems. Though the Google Translate model is the most well-known, it is not an appropriate solution for medical translations where patient safety and the protection of intellectual property are important. In practice, LSPs who offer NMT generally do so by building systems that are tailored to their customers’ needs. These engines are domain-trained and industry-specific and use high-quality translations as a reference, so the output is of higher quality.
A second counterargument refers to post-editing and quality control (QC). NMT outputs are almost never final, and unless otherwise specified, a professional translator will post-edit and polish automated translations. This ensures the output is clear, accurate, and natural-sounding before it undergoes stringent in-house QC checks.
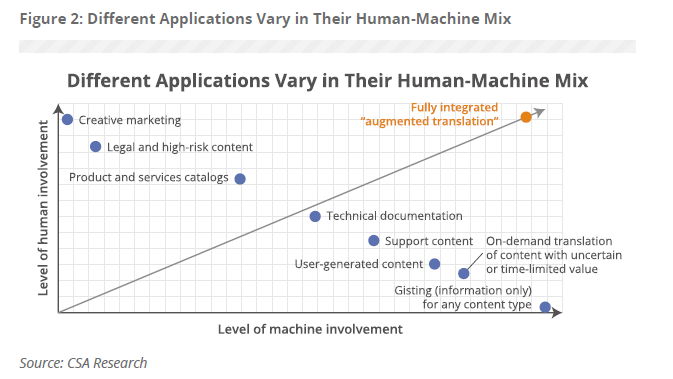
Finally, NMT is not a one-size-fits-all approach. It is important to know where machine translation is a good solution, and where it is less effective. Considerations on the type of text, terminology, and languages required all dictate whether MT should be used over standard translation. For instance, texts requiring a high degree of creativity should always be handled by human translators, whereas highly repetitive, technical documentation may be particularly suited to NMT. Figure 2 below outlines the different applications of human versus machine translation.
Myth 2: NMT will replace human translators
The flipside of the first myth is that NMT is so good, it can replace human translators. While it’s certainly true that advances in AI have dramatically improved machine learning capabilities, the technology still lags behind the proficiency of a skilled linguist.
One of the main hurdles is fluency versus accuracy (Lommel, 2017). Through deep learning and neural network configurations, NMT can produce fluent, natural-sounding translations. However, output that sounds good can conceal accuracy problems. The engine will choose those word nodes with the strongest connection, even though they may not be factually correct or relevant, thereby producing translations that are ultimately wrong.
This issue is mitigated by including post-editing as a standard procedure when managing NMT projects. In this scenario, a specialised translator edits the MT output and makes corrective and stylistic changes to refine the translation. This ensures it matches what a human translator could produce, but in a more cost- and time-efficient manner.
In fact, this reimagines the intended purpose of NMT, and more broadly AI. Rather than viewing machine translation as a way to eliminate human labour entirely, it enables a hybrid approach whereby both humans and machines work to their best abilities. NMT can thus fully automate simple, repetitive tasks that are time-consuming for human translators, and enhance human work on more complex tasks (Pielmeier, 2019) for instance with CAT tools.
Myth 3: NMT will only get bigger and better
While replacing human translators does seem far-fetched, many point to the pace of research into NMT to argue that technology is the inevitable way forward. One major player currently at the forefront of deep learning research is Google. Their Google Translate platform is only the tip of the iceberg in a series of initiatives spanning everything from health and bioscience, to quantum computing and robotics, so progress is obvious.
At the same time, progress does not entail usability. Many of these technologies are still in their infancy, with real-life applications still at a considerable distance in the future. We only need to look at the history of MT to see how arduous the journey to its current incarnation has actually been. The first MT initiatives can be traced back to the 1950s. It has taken over 70 years of stop-starts to achieve usable automated outputs, under certain conditions.
NMT itself has only started being used with some degree of regularity as recently as 2016 and has become more widespread in recent years, which goes to show how young the technology is. This makes predicting its future particularly difficult, especially when considering where NMT is on its S‑curve (Lommel, 2017).
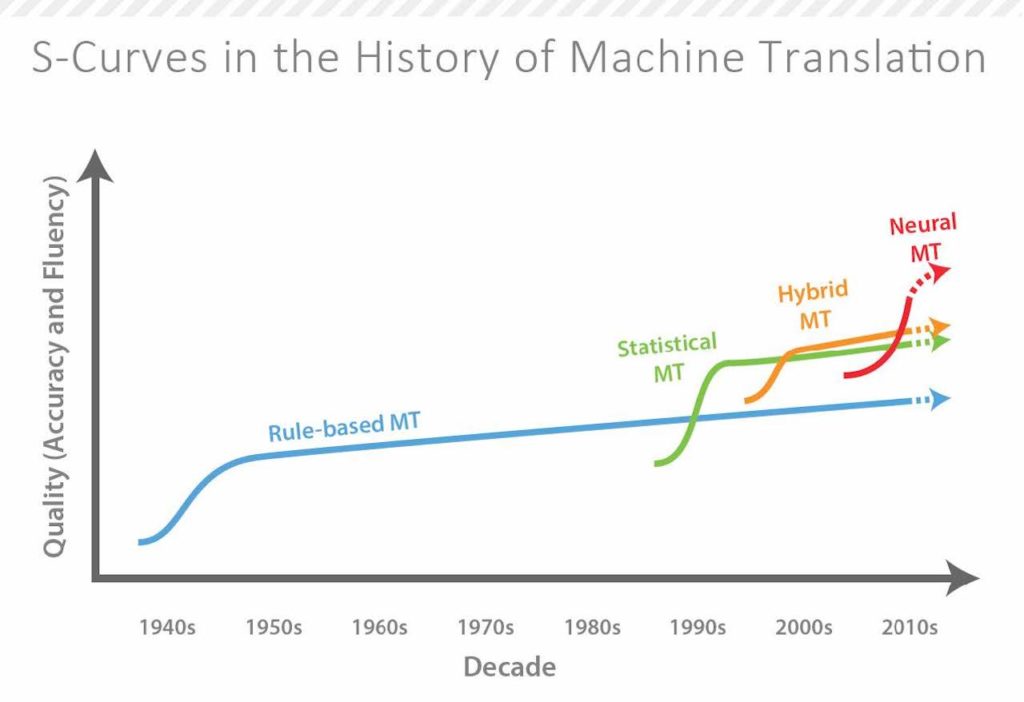
Figure 3: Each Round of MT Development Follows Its Own S-Curve (Source: Common Sense Advisory, Inc.)
All things considered, it is highly likely that NMT, whether in its current iteration or an updated version, will disrupt existing technologies and reconfigure future human-machine relationships. The key however is recalibrating our expectations of what the technology can achieve, what situations it works best in, and how it can be integrated into human work as a whole.
Next up on the blog: How to make the most of NMT.
SOURCES
Lommel, A., “Neural MT: Sorting Fact from Fiction”, Common Sense Advisory, January 2017.
Lommel, A. and Pielmeier, H., “Selling Machine Translation to Skeptical Buyers”, Common Sense Advisory, February 2020.
Pielmeier, H., “Debunking Myths about AI”, Common Sense Advisory, May 2019.
España-Bonet, C. and Costa-jussà, M.R., 2016. “Hybrid Machine Translation Overview” in Costa-jussà, M.R., Rapp, R., Lambert, P., Eberle, K., Banchs, R.E. and Babych, B. (eds.) Hybrid Approaches to Machine Translation. Amsterdam: Springer.
DeepAI. 2020. Neural Machine Translation. [online] Available at: <https://deepai.org/machine-learning-glossary-and-terms/neural-machine-translation> [Accessed 10 September 2020].
Written by Raluca Chereji, Project Manager.
Featured image credit: “Coding Image” by Markus Spiske for Tech Daily (https://techdaily.ca)









